Software Processes in Software Engineering
Chapter 2
Introduction
In the previous chapter we established that Software Engineering consist of three layers: Process, Methods and Tools. And in this chapter we will focus on the first of the three.
By now we know that Software Engineering process consist of generic activities: requirements specification, design, development, testing, deployment and evolution. And the way the activities are organized the flow, the type and details of the artifacts generated is governed by the process model that is selected.
In this chapter we will have a look at some of the most common process models.
Waterfall (linear) model
The linear or the waterfall model suggest a systematic and sequential approach to the software lifecycle. Meaning each activity completes before the next activity starts without any interaction between set activities. Figure 1 illustrates that

Figure 1 Waterfall model
This model was rarely usable. Therefor we have a slightly modified model that is used in practice. This model uses feedback loops from each phase back to the previous phase.
 Figure 2 Waterfall model with feedback loops
Figure 2 Waterfall model with feedback loops
The waterfall model presents challenges.
- Even with the feedback loops – changes to requirements are difficult to implement.
- Customers do not clearly state (define) all the requirements at the start of the project.
- A workable version of the software will not be available until late of the project.
Does this mean that the waterfall model is not useable?
Well we can use it, when the requirements are clear at the beginning and changes are not expected. However even if we have stable requirements, this model ask the customer to wait until the very end to see one-shot workable version of the program.
We will conclude with an interesting fact, the waterfall model is also commonly taught with the mnemonic A Dance in the Dark Every Monday, representing Analysis, Design, Implementation (development), Testing, Documentation and Execution (Deployment), and Maintenance.
Iterative and Incremental models
Were created in response to the weakness of the waterfall model. This two models, form the essence of evolutionary process models such as agile and RUP.
So what does iterative mean, and what does incremental mean, and is there a difference?
In Incremental the requirements are given priority. Then a number of increments are defined, where each of them contain a portion of the requirements. After we analyze each increment’s portion of the requirements in details. And then we go through the normal activities in SDLC. Increments are time-boxed which means that they have fixed, predefined maximum of time for execution. As an increment is finished it is integrated with the previous completed increments (the overall system so far). This way customers can give feedback which can derive future requirements.
How does this so far differ from the iterative approach? Well as I explained incremental delivery is a scheduling method to deliver requirements. Iterative development on the other hand is a method to refine the work done. This refinement work can be done on an increment or on full process (e.g. Waterfall). Iterative development does not mandated or is attached to incremental delivery (although frequently they are used together).
Let’s have an example in order of fully understanding the concepts. If for example we want to build a software for cars. In incremental if we have two increments, we first build the first one, then the second one after that we combine them and have a full version. However the iterative approach dictates that in the first increment we build our best guess for this software, then we continue to refine it, until we have the final version. Figure 3 illustrates the example. 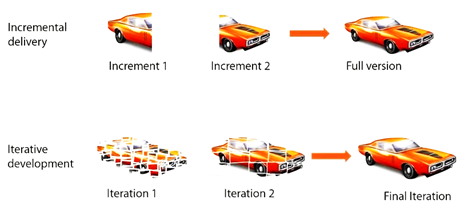
Figure 3 Incremental vs. Iterative (Car Software Example)
A good question is, can we now mix the two approaches? Absolutely. If we reuse our example with the car software, we again have two increments, however this time we build them based on our best guesses in iteration 1, then set increments are refined in iteration two until we have their final versions in iteration 3.
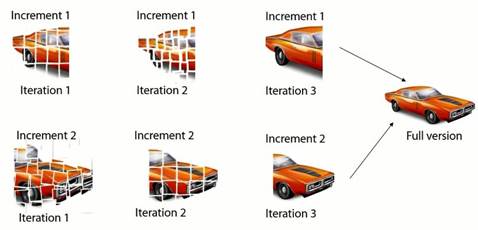 Then the final increments are combined for getting the final software. Figure 4 illustrates the combination between the two processes. Figure 4 Combination Iterative and Incremental approaches
Then the final increments are combined for getting the final software. Figure 4 illustrates the combination between the two processes. Figure 4 Combination Iterative and Incremental approaches
Prototyping
A prototype is an early sample, model, or release of a product built to test a concept or process or to act as a thing to be replicated or learned from.
We use prototypes, when 1) requirements are not clearly defined (prototype could be built to derive requirements form the customer), 2) when we have to mitigate technical or architectural risk (e.g. systems with complex architecture without known design patterns or a system implementing new technology, both cases will benefit from prototyping).
When we talk about prototyping we need to differentiate prototyping (as process model) and prototyping (as a technique). In the first case, we say the whole software is delivered with prototypes e.g. requirements are gathered, mock-up is build, design is gathered, mock-up is build and so forth. In the second case, meaning as a technique, prototyping is used within other process models. For example the Spiral model and RUP, both utilize the prototyping technique. In this case prototypes are known as “throwaway prototypes”.
It is not that common to use prototyping as a process model! Mainly because it is not that common to have projects that have 100% unclear requirements or 100% risky architectural use case.
Spiral model
The spiral model is a risk-driven process model generator for software projects. Based on the unique risk patterns of a given project, the spiral model guides a team to adopt elements of one or more process models, such as incremental, waterfall, or prototyping.
In the words of its creator (Barry Boehm), Spiral adopts a “cyclic approach for incrementally growing a system’s degree of definition and implementation while decreasing its degree of risk”.
Figure 5, Illustrates the Spiral model as presented by Barry Boehm.
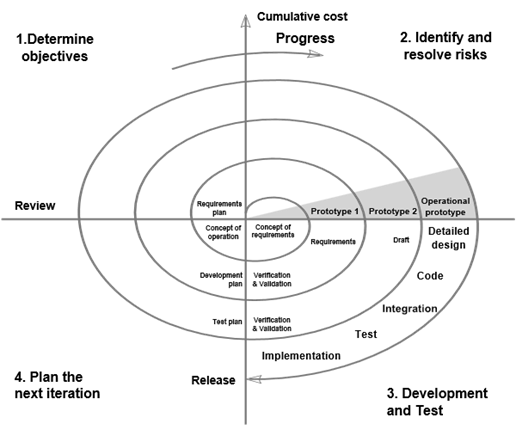
Figure 5 Spiral Model
Usually we start at 1 – Determine objectives, however in this case we start from 2. Identify and resolve risk, more precisely we build a prototype, then we get a concept of requirements, a concept of operation from there we create a requirement plan, and we start going in the spiral, until we reach the release point.
Review this short article, in order to be able to read a spiral diagram [ http://www.the-software-experts.com/e_dta-sw-process-model-spiral.php ].
The pros of using the Spiral model are:
- · Recognition of risk (Suitable for large and complex projects)
- · Adopts incremental delivery (Customers will always be involved in each iteration)
- · Uses prototyping as an effective technique to mitigate risks
The cons of using the Spiral model:
- · It is complex to manage
- · High cost (because of it’s focus on risk analysis and prototyping)
We can conclude, based on the pros and cons, that the Spiral model is suitable for large projects, and less so for small to medium size projects and/or where Agility is a key factor.
Agile model
Agile Process model is based on incremental/iterative delivery. The promise of Agile is creating a reliable software in a quick manner by eliminating the waste and overhead. Figure 6 illustrates Agile activities. 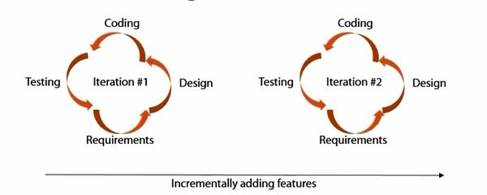 Figure 6 Agile Activities
Figure 6 Agile Activities
As we can see, no emphasis on any specific activity in any given iteration. The focus is on quick delivery of reliable software with waste eliminated. Just a quick teaser, this is different of how RUP organizes activities, more precisely it emphasize specific activity in each phase, however more on that in the next point.
The Agile manifesto is created by a group of Agile leaders. Which is the set of common philosophies that underlie the Agile methods. The Agile manifesto has values, and principles which are derived from them. Figure 7, illustrates the values. 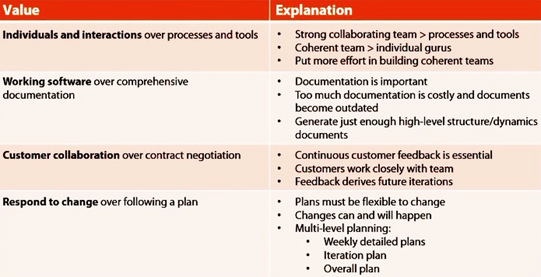 Figure 7 Agile Values
Figure 7 Agile Values
From this values the Agile manifesto bases its 12 principles, which I will not talk about, but you can read them here [http://www.agilemanifesto.org/principles.html]. Some of the most know Agile methods are: Scrum, XP (Extreme programming), Lean Software Development, Feature-Driven Development and Dynamic System Development.
Rational Unified Process (RUP)
RUP is based on incremental/iterative delivery, it is driven by risk and the development approach that uses is use-case driven and architecture centric. RUP is also a process framework, meaning process configurations are created via process customization. The configuration could support: Different team sizes (small, medium, lager) and Discipliner/Less formal development methods.
The better understand the RUP, we will use Figure 8 comparing it to Agile processes.
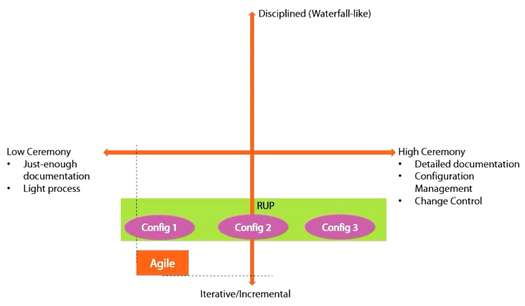
Figure 8 RUP Model
Since RUP is Iterative/Incremental it belongs to the bottom side, however the best thing about RUP is that it is a Framework, meaning the level of ceremony (artifacts created) can be adjusted, from which we can have for example RUP-Config 1, RUP-Config 2, RUP-Config 3 and so forth.
As we mentioned RUP is risk-driven and it’s development approach is both use-case and architectural driven. We will explore this statement more by explaining RUP’s phases and associated milestones.
The RUP has determined a project life-cycle consisting of four phases. Inception, Elaboration, Construction and Transition. This phases occur in a linear fashion, meaning the phase must end before the next start. However there are multiple iterations inside each phase, the number of iteration is determined by the amount of risks needed to be mitigated.
In the Inception phase – we aim to scope the system adequately as a basis for validating initial costing and budgets. In this phase the business case which includes business context, success factors (expected revenue, market recognition, etc.), and financial forecast is established. The milestone is Lifecycle objective which mitigates Business risks. In the Elaboration phase the primary objective is to mitigate the key risk items identified by analysis up to the end of this phase. In Construction phase the primary objective is to build the software system. This phase produces the first external release of the software. Its conclusion is marked by the initial operational capability milestone. Transition phase the primary objective is to ‘transit’ the system from development into production, making it available to and understood by the end user. Figure 9 illustrates all the explained concepts above.
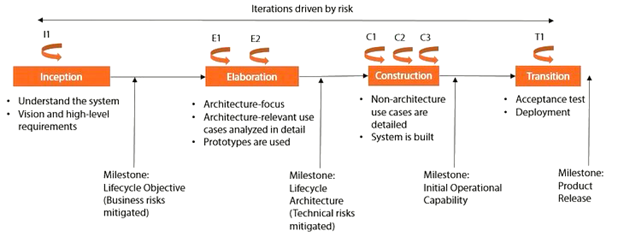
Figure 9 RUP - Phases and milestones
Specialized Models
In addition to the process models discussed in the previous points, there are a verity of models used for certain kinds of projects, these models are called Specialized models. They have the characteristics of one of the models we already discussed, but they tend to have special techniques/methods for certain type of problems. Example of such specialized models are Component-Based development, Formal Methods and Aspect-Oriented development.
Component-Based development
This is a development approach based on reuse of software components. Commercial of-the-shelf (COTS) components are developed by vendors and have well-defined interfaces, which enables them to be integrated in the software. Custom components can be built, in addition to COTS, with reusability in mind.
In this development approach the architecture of the system is centered around components integration. And testing is based on messages exchange between components.
Formal methods
This is a way of using formal mathematical specifications, meaning requirements are represented by mathematical equation with precisely define vocabulary, syntax and semantics. Due to this requirements verification, design and code generation happen automatically.
Pros of using this type of methods arethat they solve the requirements ambiguity problems of non-formal methods and that they are suitable for the development of safety-critical systems (e.g. Aircraft navigation system). However cons of using formal methods are that they are time consuming and expensive, also very few developer possess the knowledge needed to use them.
Aspect-Oriented development
In development, a cross-cutting concern is a party of aspect that spans the entire architecture. In other words this is functionality that is required in several different places in the program and comes across various functions, components and services. This cross-cutting concerns are mostly non-functional requirements, such as security, logging, caching and so on.
Aspect-Oriented development defines these concerns as Aspects and provided methodology to specify, design and develop these Aspects. Since Aspects are isolated (i.e. developed and maintained separately), they can be composed and reused more easily. And this results in much more clear and maintainable system code.
And now, which process model should I use?
After examining the most common process models the natural question is “which process model to use”?
The simplest answer is that there is no one-size-fits-all solution. No absolute right or wrong answer! In general any process is good process, if it helps you reach the end target: delivering the right software, with the appropriate level of quality and within the planned time and budget.
Having said this, I need to tell you that there are recommendations, based on experience and lessons learned by Software Engineers, that you could use.
Teams do not have to limit themselves to a single process and can select from multiple process models, and each project is suitable for a certain scenario or type of project. In order to do that the organization needs a process filter. The most important thing is to standardize the filter criteria. After evaluating the project against these criteria, it is then decided which process to use for the project.
The criteria in the filter will definitely vary from one organization to another. However Figure 10, gives you a suggestive method that can get you going.
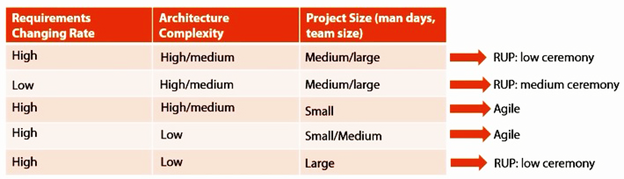
Figure 10 Example of Process Filter
This of course is just one way of doing a process filter and you could add many more factors (e.g. team capability, organization maturity and so on). The important thing however is to determine a way to select a process model objectively, rather to subjectively.