Monolith vs Microservices Architecture
Monolith architecture
An application has a monolithic architecture if it contains the entire application code in a single codebase.
A monolithic software application is a self-contained, single-tiered software application unlike the microservices architecture, where different modules are responsible for running respective tasks and features of an app.
The diagram below represents a monolithic architecture:
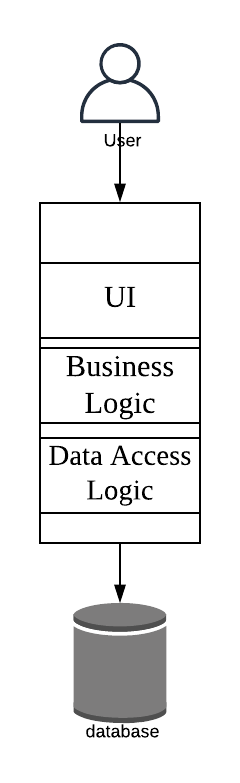
In a monolithic web-app all the different layers of the app, UI, business, data access etc. are in the same codebase.
We have the Controller, then the Service Layer interface, Class implementations of the interface, the business logic goes in the Object Domain model, a bit in the Service, Business and the Repository/DAO [Data Access Object] classes.
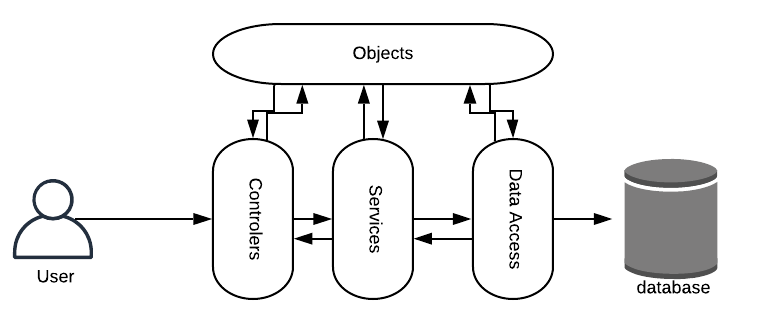
Monolithic apps are simple to build, test & deploy in comparison to a microservices architecture.
There are times during the initial stages of the business when teams chose to move forward with the monolithic architecture & then later intend to branch out into the distributed, microservices architecture.
Well, this decision has several trade-offs. And there is no standard solution to this.
In the present computing landscape, the applications are being built & deployed on the cloud. A wise decision would be to pick the loosely coupled stateless microservices architecture right from the start if you expect things to grow at quite a pace in the future.
Because re-writing stuff has its costs. Stripping down things in a tightly coupled architecture & re-writing stuff demands a lot of resources & time.
On the flip side, if your requirements are simple why bother writing a microservices architecture? Running different modules in conjunction with each other isn’t a walk in the park.
Pros
- Simplicity
Monolithic applications are simple to develop, test, deploy, monitor and manage since everything resides in one repository.
There is no complexity of handling different components, making them work in conjunction with each other, monitoring several different components & stuff. Things are simple.
Cons
- Continuous Deployment
Continuous deployment* is a pain in case of monolithic applications as even a minor code change in a layer needs a re-deployment of the entire application.
- Regression Testing
We need a thorough regression testing of the entire application after the deployment is done as the layers are tightly coupled with each other. A change in one layer impacts other layers significantly.
- Single Points Of Failure
Monolithic applications have a single point of failure. In case any of the layers has a bug, it has the potential to take down the entire application.
- Scalability Issues
Flexibility and scalability are a challenge in monolith apps as a change in one layer often needs a change and testing in all the layers. As the code size increases, things might get a bit tricky to manage.
- Cannot Leverage Heterogeneous Technologies
Building complex applications with a monolithic architecture is tricky as using heterogeneous technologies is difficult in a single codebase due to the compatibility issues.
- Not Cloud-Ready, Hold State
Generally, monolithic applications are not cloud-ready as they hold state in the static variables. An application to be cloud-native, to work smoothly & to be consistent on the cloud has to be distributed and stateless.
When do I pick a monolith architecture?
Monolithic applications fit best for use cases where the requirements are pretty simple, the app is expected to handle a limited amount of traffic. One example of this is an internal tax calculation app of an organization or a similar open public tool.
These are the use cases where the business is certain that there won’t be an exponential growth in the user base and the traffic over time.
There are also instances where the dev teams decide to start with a monolithic architecture and later scale out to a distributed microservices architecture.
This helps them deal with the complexity of the application step by step as and when required. This is exactly what LinkedIn did.
Microservice architecture
In a microservices architecture, different features/tasks are split into separate respective modules/codebases which work in conjunction with each other forming a large service as a whole.
Remember the Single Responsibility & the Separation of Concerns principles? Both the principles are applied in a microservices architecture.
This particular architecture facilitates easier & cleaner app maintenance, feature development, testing & deployment in comparison to a monolithic architecture.
Imagine accommodating every feature in a single repository. How complex things would be? It would be a maintenance nightmare.
Also, since the project is large, it is expected to be managed by several different teams. When modules are separate, they can be assigned to respective teams with minimum fuss, smoothening out the development process.
And did I bring up scalability? To scale, we need to split things up. We need to scale out when we can’t scale up further. Microservices architecture is inherently designed to scale.
The diagram below represents a microservices architecture:
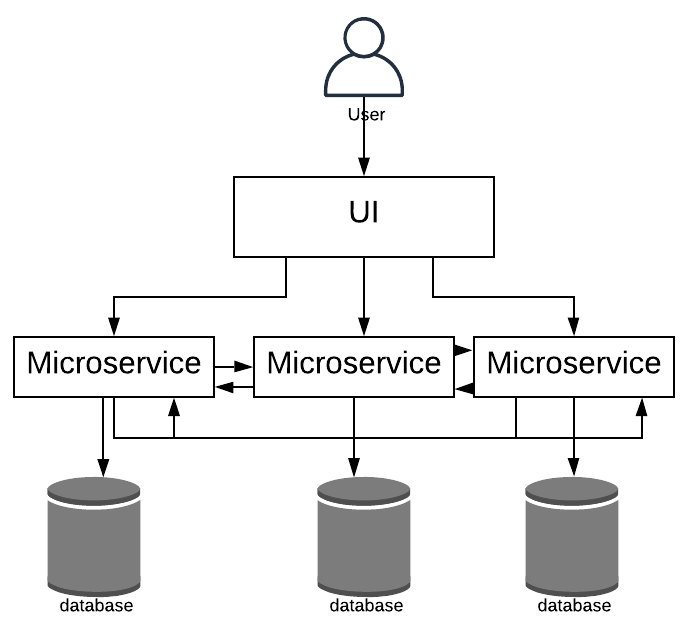
Pros
- No Single Points Of Failure
Since microservices is a loosely coupled architecture, there is no single point of failure. Even if a few of the services go down, the application as a whole is still up.
- Leverage the Heterogeneous Technologies
Every component interacts with each other via a REST API Gateway interface. The components can leverage the polyglot persistence architecture & other heterogeneous technologies together like Java, Python, Ruby, NodeJS etc.
Polyglot persistence is using multiple databases types like SQL, NoSQL together in an architecture. I’ll discuss it in detail in the database lesson.
- Independent & Continuous Deployments
The deployments can be independent and continuous. We can have dedicated teams for every microservice, it can be scaled independently without impacting other services.
Cons
- Complexities In Management
Microservices is a distributed environment, where there are so many nodes running together. Managing & monitoring them gets complex.
We need to setup additional components to manage microservices such as a node manager like Apache Zookeeper, a distributed tracing service for monitoring the nodes etc.
We need more skilled resources, maybe a dedicated team to manage these services.
- No Strong Consistency
Strong consistency is hard to guarantee in a distributed environment. Things are Eventually consistent across the nodes. And this limitation is due to the distributed design.
When do I pick a microservices architecture?
The microservice architecture fits best for complex use cases and for apps which expect traffic to increase exponentially in future like a fancy social network application.
A typical social networking application has various components such as messaging, real-time chat, LIVE video streaming, image uploads, Like, Share feature etc.
In this scenario, I would suggest developing each component separately keeping the Single Responsibility and the Separation of Concerns principle in mind.
Writing every feature in a single codebase would take no time in becoming a mess.
Trade-offs Monolith vs Microservices
By now, we have understood what is a monolith, what is a microservice, their pros & cons & when to pick which? Lets continue our discussion a bit further on the trade-offs that are involved when choosing between the monolith and the microservices architecture to design our application.
Fault Isolation
When we have a microservices architecture in place it’s easy for us to isolate faults and debug them. When a glitch occurs in a particular service, we just have to fix the issue in that service without the need to scan the entire codebase in order to locate and fix that issue. This is also known as fault isolation.
Even if the service goes down due to the fault, the other services are up & running. This has a minimal impact on the system.
Development Team Autonomy
In case of a monolith architecture if the number of developers and the teams working on a single codebase grows beyond a certain number. It may impede the productivity and the velocity of the teams.
In this scenario, things become a little tricky to manage. First off, as the size of the codebase increases, the compile-time & the time required to run the tests increases too. Since, in a monolith architecture, the entire codebase has to be compiled as opposed to just compiling the module we work on.
A code change made, in the codebase, by any other team has a direct impact on the features we develop. It may even break the functionality of our feature. Due to this a thorough regression testing is required every time anyone pushes new code or an update to production.
Also, as the code is pushed to production, we need all the teams to stop working on the codebase until the change is pushed to production.
The code pushed by a certain team may also require approval from other teams in the organization working on the same codebase. This process is a bottleneck in the system.
On the contrary, in the case of microservices separate teams have complete ownership of their codebases. They have a complete development and deployment autonomy over their modules with separate deployment pipelines. Code management becomes easier. It becomes easier to scale individual services based on their traffic load patterns.
So, if you need to move fast, launch a lot of features quick to the market and scale. Moving forward with microservices architecture is a good bet.
Having a microservices architecture sounds delightful but we cannot ignore the increase in the complexity in the architecture due to this. Adopting microservices has its costs.
With the microservices architecture comes along the need to set up distributed logging, monitoring, inter-service communication, service discovery, alerts, tracing, build & release pipelines, health checks & so on. You may even have to write a lot of custom tooling from scratch for yourself.
So, I think you get the idea. There are always trade-offs involved there is no perfect or the best solution. We need to be crystal on our use case and see what architecture suits our needs best.
Let’s understand this further with the help of a real-world example of a company called Segment that started with a monolith architecture, moved to microservices and then moved back again to the monolith architecture.
Use case – from Monolith to Microservices and back again to Monolith
Segment is a customer data platform that originally started with a monolith and then later split it into microservices. As their business gained traction, they again decided to revert to the monolith architecture.
Segment engineering team split their monolith into microservices for fault isolation & easy debugging of issues in the system.
Fault isolation with microservices helped them minimize the damage a fault caused in the system. It was confined to a certain service as opposed to impacting, even bringing down the entire system as a whole.
The original monolith architecture had low management overhead but had a single point of failure. A glitch in a certain functionality had the potential to impact the entire system.
Segment integrates data from many different data providers into their system. As the business gained traction, they integrated more data providers into their system creating a separate microservice for every data provider. The increase in the number of microservices led to an increase in the complexity of their architecture significantly, subsequently taking a toll on their productivity.
The defects with regards to microservices started increasing significantly. They had three engineers straight up just dedicated to getting rid of these defects to keep the system online. This operational overhead became resource-intensive & slowed down the organization immensely.
To tackle the issue, they made the decision to move back to monolith giving up on fault isolation and other nice things that the microservices architecture brought along.
They ended up with an architecture having a single code repository that they called Centrifuge that handled billions of messages per day delivered to multiple APIs.
High-level architecture
Segment’s data infrastructure ingests hundreds of thousands of events per second. These events are then directed to different APIs & webhooks via a message queue. These APIs are also called as server-side destinations & there are over a hundred of these destinations at Segment.
When they started with a monolith architecture. They had an API that ingested events from different sources and those events were then forwarded to a distributed message queue. The queue based on configuration and settings further moved the event payload to different destination APIs.
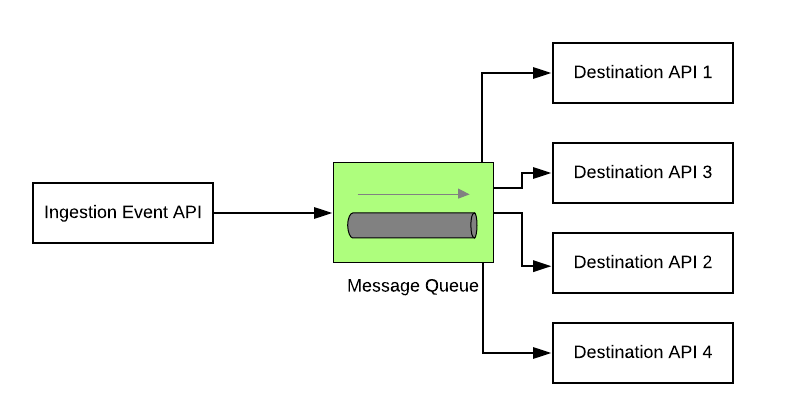
In the monolithic architecture, as all the events were moved into a single queue, some of the events often failed to deliver to the destinations and were retried by the queue after stipulated time intervals.
This made the queue contain both the new as well as the failed events waiting to be retried. This eventually flooded the queue resulting in a delay of the delivery of events to the destinations.
To tackle the queue flooding issue, the engineering team at Segment split the monolith into microservices and created a separate microservice for every destination.
Every service contained its own individual distributed message queue. This helped cut down the load on a single queue & enabled the system to scale also increasing the throughput.
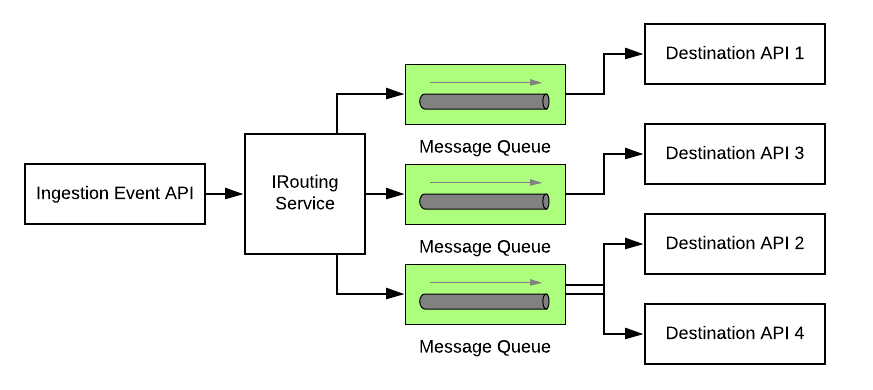
In this scenario, even if a certain queue got flooded it didn’t impact the event delivery of other services. This is how Segment leveraged fault isolation with the microservices architecture.
Over time as the business gained traction additional destinations were added. Every destination had a separate microservice and a queue. The increase in the number of services led to an increase in the complexity of the architecture.
Separate services had separate event throughput & traffic load patterns. A single scale policy couldn’t be applied on all the queues commonly. Every service and the queue needed to be scaled differently based on its traffic load pattern. And this process had to be done manually.
Auto-scaling was implemented in the infrastructure but every service had distinct CPU & memory requirements. This needed manual tuning of the infrastructure. This meant - more queues needed more resources for maintenance.
To tackle this, Segment eventually reverted to monolith architecture calling their architecture as Centrifuge that combined all the individual queues for different destinations into a single monolith service.
The info that I have provided on Segment architecture in this lesson is very high-level. If you wish to go into more details, want to have a look at the Centrifuge architecture. Do go through these resources -
Goodbye Microservices: From 100s Of Problem Children To 1 Superstar
Centrifuge: A Reliable System For Delivering Billions Of Events Per Day